

DFT 是什么?
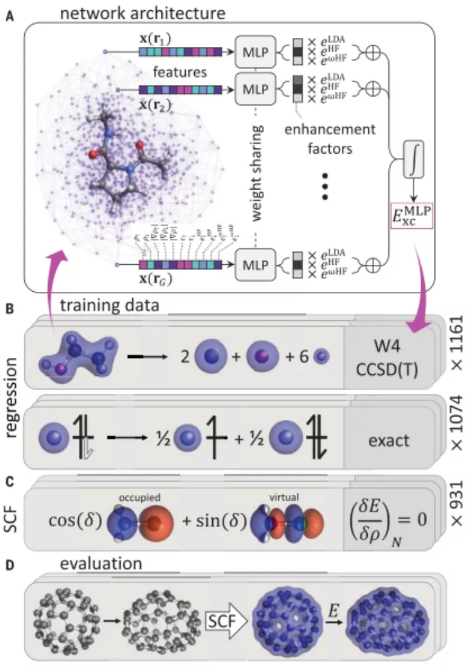
DeepMind 的神经网络可以用于构建比先前更精确的电子密度和相互作用图,摆脱了此前的诸多限制。作为 DeepMind 的研究科学家,James Kirkpatrick 和他的同事使用 DeepMind 平台开发了“DM21”(DeepMind 2021)框架,可以利用精确的化学数据和分数电荷约束来训练神经网络。
根据研究报告,DM21 能够避免两个重要的系统误差(离域误差和自旋对称性)的破坏,从而学习泛函,更好地描述广泛的化学反应类别。研究人员用 2235 个化学反应示例训练了他们的人工智能,并提供了有关所涉及的电子和系统能量的信息。其中,1074 个代表了分数电子会对传统 DFT 分析造成问题的系统。然后,他们将人工智能应用于未包含在训练数据中的化学反应。DeepMind 21 不仅正确地表示了分数电子,而且其结果比传统的 DFT 分析更精确。它甚至可以处理关于具有奇怪属性的原子的数据,这些数据与训练数据中的任何东西都不相似。DM21 正确描述了人工电荷离域和强相关性的典例,并且在主族(main-group)原子和分子的全面基准评估上优于传统泛函。此外,DM21 可以准确地模拟复杂系统,如氢键链(hydrogen chains)、带电荷 DNA 碱基对和双自由基体系的过渡态。更为关键的是,该研究中的方案依赖于不断改进的数据和约束,因此,它代表着一条通向泛函的可行途径。
DM21 之所以极大地提高了性能,因为它服从两类分数电荷系统的约束:
1)具有非整数总电荷的分数电荷(FC, Fractional Charge)系统;
2)具有非整数自旋磁化的分数自旋(FS, Fractional Spin)系统。
尽管 FC 和 FS 系统是虚构的,但实际电荷密度可以包括具有 FC 或 FS 特性的区域,因此,正确建模这些理想化问题有助于确保泛函在各种分子和材料中的正确表现。
实验结果显示,在 55 个不同热化学分子性质、大而多样的数据集上,DM21 的加权绝对误差为 4 kcal/mol。这个非常小的误差与大多数泛函误差相比,是由大量精心选择的成分和拟合的分子数据造成的。无论是否包含分数电荷和自旋数据,误差本质上是相同的。然而,这些数据的加入提高了 DM21 在电荷转移和强相关性问题上的性能。

DM21可以与强约束和适当赋范泛函(SCAN, Strongly Constrained and Appropriately Normed)进行比较,该泛函是通过假设方程满足 17 个精确约束,但不满足分数电荷和自旋约束而创建的。SCAN 产生的误差为 8 kcal/mol。然而,当 SCAN 进行密度校正时,该误差降低到 6 kcal/mol。这说明,密度校正可以消除 SCAN 的电荷转移误差。
Jon Perdew 在相关观点中写道:“由 Kirkpatrick 等人开发的 DM21 的重要性,并不在于产生了最终密度泛函,而是用一种 AI 方法解决了分数电子和自旋问题,该问题一直无法通过直接解析方法来创建泛函。”
整个研究工作表明,通过结合约束满足和 AI 拟合大而多样的数据集,可以设计出更具有预测性的精确密度函数。
DeepMind 演示了神经网络如何提高密度泛函的近似值,有力地显示了 DL 在量子力学水平上精确模拟物质的前景。此外,DeepMind 还开源了代码,为研究者提供了探索研究的基础。对于这一成果,James Kirkpatrick 表示:“了解微观尺度现象对于帮助我们应对 21 世纪的一些重大挑战,从清洁电力到塑料污染,正变得越来越重要……这项研究朝着正确方向迈出的关键一步,使我们能够更好地理解电子之间的相互作用,而电子就是将分子粘在一起的‘胶水’。”
从短期来看,这将使研究人员能够通过代码的可用性,获得一个改进的精确密度函数的近似值;从长远来看,这是 DL 在量子力学水平上精确模拟物质的更进一步——这可能使研究人员能够在纳米水平上探索材料、药物和催化剂的问题,从而在计算机上实现材料设计。